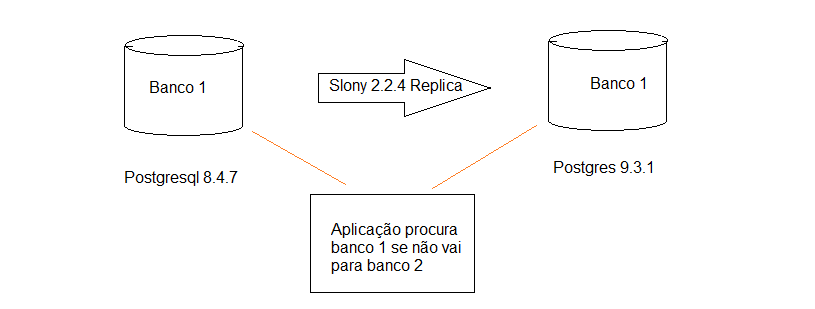
Necessitei criar um arquivo formatado:
select '<
doc>
''||E'\n'
'<
field name="cd_email
">
'|| cd_email ||'</field>'||E'\n'||
'<
field name="ds_remetente_email
">
'|| ds_remetente_email ||'</field>'||E'\n'||
'<
field name="ds_destinatario_email
">
'|| ds_destinatario_email ||'</field>'||E'\n'||
'<
field name="ds_copia
">
'|| ds_copia ||'</field>'||E'\n'||
'<
field name="ds_assunto
">
'|| ds_assunto ||'</field>'||E'\n'||
'<
field name="ds_mensagem_txt
">
'|| strip_tags(ds_mensagem_txt) ||'</field>'||E'\n'||
'<
field name="dt_abertura
">
'|| dt_abertura ||'</field>'||E'\n'||
'<
field name="dt_envio
">
'|| dt_envio ||'</field>'||E'\n'||
'<
field name="dt_recebimento
">
'|| dt_recebimento ||'</field>'||E'\n'||
'<doc>'||E'\n'||E'\n'FROM
crm.tb_email;
A solução acima gera um trabalho muito grande para escrever a consulta.
Com a expressão abaixo tem-se:
select 'xmlelement(name field, xmlattributes(''' || coluna || ''' as name), ' ||coluna|| '),' from
(select a.attname as coluna
from pg_catalog.pg_attribute a inner join pg_stat_user_tables c on a.attrelid = c.relid
WHERE a.attnum > 0
and NOT a.attisdropped
and c.relname = '
tb_email') as foo
o seguinte resultado:
xmlelement(name field, xmlattributes('cd_email' as name), cd_email),
xmlelement(name field, xmlattributes('cd_caixa_email' as name), cd_caixa_email),
xmlelement(name field, xmlattributes('cd_usuario_cadastro' as name), cd_usuario_cadastro),
xmlelement(name field, xmlattributes('cd_usuario_abertura' as name), cd_usuario_abertura),
xmlelement(name field, xmlattributes('cd_usuario_responsavel' as name), cd_usuario_responsavel),
xmlelement(name field, xmlattributes('cd_status_documento' as name), cd_status_documento),
xmlelement(name field, xmlattributes('cd_status_fluxo' as name), cd_status_fluxo),
xmlelement(name field, xmlattributes('ds_remetente_email' as name), ds_remetente_email),
xmlelement(name field, xmlattributes('ds_destinatario_email' as name), ds_destinatario_email),
xmlelement(name field, xmlattributes('ds_copia' as name), ds_copia),
xmlelement(name field, xmlattributes('ds_assunto' as name), ds_assunto),
xmlelement(name field, xmlattributes('ds_mensagem' as name), ds_mensagem),
xmlelement(name field, xmlattributes('nu_protocolo_email' as name), nu_protocolo_email),
xmlelement(name field, xmlattributes('ds_mensagem_txt' as name), ds_mensagem_txt),
xmlelement(name field, xmlattributes('ds_mensagem_srch' as name), ds_mensagem_srch),
xmlelement(name field, xmlattributes('dt_abertura' as name), dt_abertura),
xmlelement(name field, xmlattributes('dt_envio' as name), dt_envio),
xmlelement(name field, xmlattributes('dt_recebimento' as name), dt_recebimento),
xmlelement(name field, xmlattributes('dt_auditoria' as name), dt_auditoria),
com o resultado pode-se criar uma nova consulta
select '< doc >',
xmlelement(name field, xmlattributes('cd_email' as name), cd_email),
xmlelement(name field, xmlattributes('cd_caixa_email' as name), cd_caixa_email),
xmlelement(name field, xmlattributes('cd_usuario_cadastro' as name), cd_usuario_cadastro),
xmlelement(name field, xmlattributes('cd_usuario_abertura' as name), cd_usuario_abertura),
xmlelement(name field, xmlattributes('cd_usuario_responsavel' as name), cd_usuario_responsavel),
xmlelement(name field, xmlattributes('cd_status_documento' as name), cd_status_documento),
xmlelement(name field, xmlattributes('cd_status_fluxo' as name), cd_status_fluxo),
xmlelement(name field, xmlattributes('ds_remetente_email' as name), ds_remetente_email),
xmlelement(name field, xmlattributes('ds_destinatario_email' as name), ds_destinatario_email),
xmlelement(name field, xmlattributes('ds_copia' as name), ds_copia),
xmlelement(name field, xmlattributes('ds_assunto' as name), ds_assunto),
xmlelement(name field, xmlattributes('ds_mensagem' as name), ds_mensagem),
xmlelement(name field, xmlattributes('nu_protocolo_email' as name), nu_protocolo_email),
xmlelement(name field, xmlattributes('ds_mensagem_txt' as name), ds_mensagem_txt),
xmlelement(name field, xmlattributes('ds_mensagem_srch' as name), ds_mensagem_srch),
xmlelement(name field, xmlattributes('dt_abertura' as name), dt_abertura),
xmlelement(name field, xmlattributes('dt_envio' as name), dt_envio),
xmlelement(name field, xmlattributes('dt_recebimento' as name), dt_recebimento),
xmlelement(name field, xmlattributes('dt_auditoria' as name), dt_auditoria),
'< / doc >'
from crm.tb_email